I got the following catalog in the mail today, addressed to me:

I am neither female, nor am I African-American, nor do I plan on becoming either at any point in my life. Any ideas on why I received this?
I got the following catalog in the mail today, addressed to me:
I am neither female, nor am I African-American, nor do I plan on becoming either at any point in my life. Any ideas on why I received this?
The Register recently had an an interesting article on GFS2: the replacement for the Google File System. It offers insight on the problems Google is facing with the aging GFS. In today's world of video streaming, GMail account checking, and more, the GFS model doesn't hold up as it once did. According to the article, the new Caffeine search engine that Google is rolling out supposedly uses this new back end, resulting in faster search results. It should be interesting to see what other benefits come our way as Google tinkers with their engine.
Gabe Newell, from Valve software, recently conducted a focus group session with deaf gamers. Three videos are available of this event: Part One, Part Two, and Part Three. Note that the audio quality is, ironically, pretty bad in each video.
One of the most interesting tidbits from these videos involves Valve's desire to introduce a deaf character into a future game (possibly in the Half Life universe). An idea is floated where Alyx has taught Dog sign language, based on a past crush she had with a deaf individual. In essence, it would be an excuse for Valve to develop the necessary technology for characters to sign. Pretty cool.
I think it's great that Valve is doing this. In the accessibility world, blind people get nearly all of the focus. For a gaming company to branch out into this realm is really quite remarkable. I'm looking forward to see how Valve implements this new technology, and I'm excited to see where the Half Life story goes with this (assuming, of course, that Half Life is the intended universe for this work).
Way back in January, I bit the bullet and signed up for an account at Mint.com, a free, web-based personal finance tool. Moving into a new house had brought with it a substantial amount of financial responsibility, and I wanted an easy way to track where my money was going. Now that I've been using it for 7 months or so, I thought I'd post a few thoughts on the service.
Before I get too far into my description of the service, let me talk about security (which was my number one concern when I joined). When you sign up for an account at Mint.com, you give them your personal login credentials for things like your bank account, credit card, mortgage, etc. I'll give you a moment to recover from your heart attack. Now that you're back, let's go over how Mint keeps that information safe. First of all, Mint collects no personally identifying information. When you sign up, all they ask for is:
That's it. No name, no social security number, no address; none of that. Second, and most importantly in my opinion, is the fact that Mint is a read-only service. You cannot pay bills via Mint, you cannot transfer money via Mint, and you cannot withdraw money via Mint. The service is intended to be used as an organization and analyzing tool.
Third, Mint stores your usernames and passwords separately from your financial data. In other words, your credentials are stored on separate physical servers. All of this is handled with the same security used by banks for electronic transactions (in fact, the software being used behind the scenes is, in many cases, the exact same software being used by banks on a daily basis). Even though you're providing login information, I like the fact that, at any time, I can change my login info to essentially lock out the Mint service. If Mint ever gets hacked, it's just a matter of changing my passwords at my various financial institutions to keep any "bad guys" out.
The security page at Mint.com has lots more information, along with a video from the CEO describing how their security works in more detail. I recommend checking it out.
For most folks, the meat and potatoes of Mint.com comes in its budgeting and cash flow tools. Mint allows you to set a budget for various categories each month, and it will even modify your budget over time as it analyzes your spending habits (which I think is a great feature). I only casually use budgets, so I'm going to gloss over that part of the site for now.
One of my favorite parts of Mint is the cash flow analysis graph. Unfortunately, this graph is limited to six months at a time (I wish I could specify a larger duration, such as a year). I'm hoping that Mint will improve this functionality, but for now I can live with it. Here's a snapshot of my cash flow graph as of last night (the values have been censored to protect the innocent):
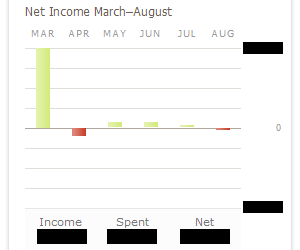
With this handy graph, I can see whether or not I'm making money each month. As you can see, March was a great month for me income-wise, thanks to a first-time home buyer's loan, and a sizable return on my taxes. The following month was a net loss since I made an extra mortgage payment (again, thanks to that sizable income in March). And each month since that time, I've been saving more than I spend (August is in the red, but I haven't been paid yet). When I log into my Mint account, this is the first graph I look at and the one I find most interesting.
The other most useful view to me is the Transactions view. It lists all of the transactions in all of your accounts: withdrawals from ATMs, purchases you've made on your credit cards, interest earned in your bank accounts, etc. In this view you can categorize various purchases and filter the data a number of ways. Rules can be created to automatically rename and categorize recurring transactions. Think of it as a ledger specifying each and every transaction that happens. I personally use this view to keep track of whether or not I've made certain payments, and to keep track of how much interest I'm earning each month in my bank accounts.
Mint makes it easy to set up alerts for various things. I have several alerts set up to watch for unusual spending. For example, whenever a very large transaction comes through (> $1000, for example), I can get an email or text message. This capability is very useful for keeping an eye on your accounts, allowing you to quickly respond to transactions that you may not have made. I consider this an extra safety net in watching for stolen credit card information, a hacked bank account, etc. You can also elect to get weekly summary emails, making it easy to keep tabs on your funds without even having to log in.
Spending trends is a great way to see how your money is divided up each month. Here's a snapshot of my spending trends for this month (it's admittedly not as exciting as a full month's worth of data would be):
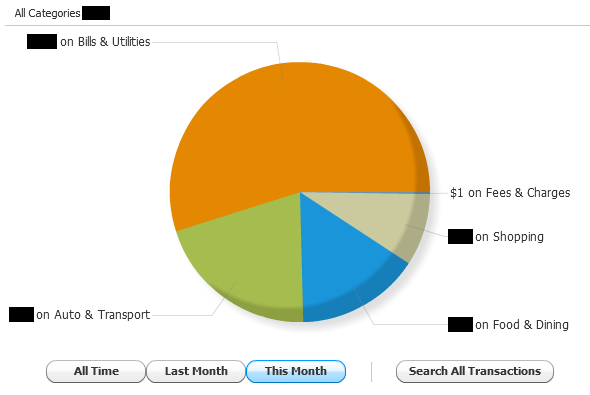
I pay the vast majority of my bills at the beginning of the month, which accounts for the large chunk of money being sent to that category so far. Usually, my mortgage payment (filed under the 'Home' category) is the largest chunk, but I have yet to make that payment this month. As I said, the more data you have for a month, and the more categories are represented, the more interesting this pie chart becomes. It's cool to see where the bulk of your expenses goes each month.
It's also worth pointing out that the graph is interactive. Click a slice of the pie, and the chart will zoom into that slice, and break down how that slice is, itself, broken up. Very slick.
One other spending view that Mint offers is the "SpendSpace" view. I rarely use this, but it's occasionally fun to look at. Here is my grocery spending over the past six months as compared to other folks in North Carolina:
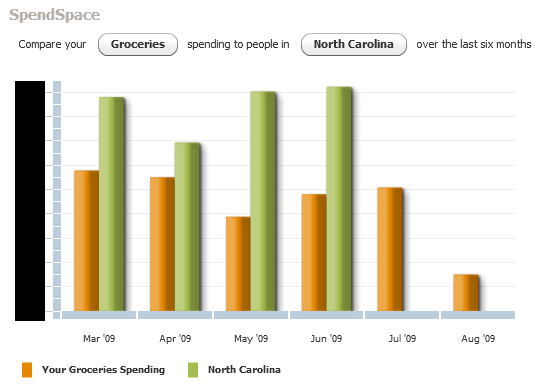
As you can see, I spend way less than the average family for groceries (which makes sense, seeing as I'm only feeding myself). The missing data for July is odd; either the data has yet to be loaded up, or no one in North Carolina bought groceries in July. I'm guessing it's the latter. ;-)
I only have a few gripes with Mint. Every so often, Mint will have trouble connecting to my bank accounts. This can occasionally become an annoyance, especially when the connection failures last for a few days. All of the problems eventually clear up, however, and the service catches up with all the transactions it missed in the mean time.
There are ways the tool could be improved. I wish the cash flow view allowed you to view longer periods of time, and I've seen people calling for a cash flow predictor, which is an interesting idea. The folks at Mint seem willing to listen to the public, which is great. Hopefully some of these improvements will show up at some point in the future.
Overall, I'm incredibly pleased with Mint. There are plenty of other features that I haven't listed here, many of which you may find useful (learn more at the Mint features page). Signing up for an account is free and easy, as long as you're willing to provide your financial login information.
Jeffrey Zeldman has written an interesting article on URL shortening and, more specifically, how he rolled his own using a plugin for WordPress. He also points to an excellent article written by Joshua Schachter, describing the benefits and pitfalls of link shortening utilities. Both articles are worthy reads. I suggest reading Joshua's article before Jeffrey's.
Do you use URL shortening services? I mainly use bit.ly at Twitter, mostly because that's what everyone else seemed to use. Have you found some services to be better than others?
When I moved into my house last year, I bought an LG front-load washing machine. Having never owned or operated a front-load washer, I didn't quite know what to expect. For those who don't already know, front-load washing machines typically spin clothes at a very high rate of speed (mine tops out at 1050 RPM), removing a large amount of excess water in the process. This high speed spin process usually results in substantial vibration. The problem is compounded when the washer is located in an upstairs room (as mine is), and not on a solid, ground level floor (I've read that concrete floors are ideal).
Not knowing about this at the time, I was really surprised to see that my entire house vibrated when I washed a load of laundry. The shaking and noise got bad enough that I decided to look into solutions to the problem. I read some about vibration reducing pads online, and picked up a set at a local home improvement store (for about $30, if I remember correctly). After installing the pads with the help of my dad, I noted an improvement in the amount of vibration in the floor. However, the vibration was still bad enough to cause some sympathetic vibrations in my dryer (a major source of noise, oddly enough). Also, these pads were flat on top, so the washer tended to 'walk' off of them when a load was particularly unbalanced. Like before, the problem became bad enough to look for another solution.
I found another pair of pads online that had good reviews, and picked up a set (here's a link: Good Vibrations Washing Machine Pads). These pads are round, not square like the others I had bought, and have a recessed area for the foot of the washing machine.
Wow! Not only does the washer no longer walk off of the pads (thanks to that recessed area), but the vibration in the floor has been reduced by what seems like an order of magnitude! My dryer no longer suffers from "sympathetic-vibration-syndrome," and the entire wash cycle is noticeably quieter. A set of four pads are $36.95 as of this writing (plus shipping). The sellers accept PayPal, so if you've got some money stored up (like I did, thanks to a recent donation to Born Geek), you can pick up a set pretty easily.
If you've got a front-load washer and have issues with large vibrations, I recommend the "Good Vibrations" pads. They work remarkably well.
I have tweaked the style sheet here at Born Geek, adding eye-candy support to WebKit enabled browsers (Safari and Chrome). I've also squashed some minor bugs. Let me know if you spot something that needs correcting.
[I originally tweeted some of the following thoughts, but decided a blog post would be a better place to share them, hence the disappearance of said tweets.]
I've recently been going through the original Star Trek movies (with William Shatner, et al). Prior to watching the films, I started with the first season of the original series, which is available instantly on Netflix. Sure it's dated, but I think the original show is terrific. There are a number of interesting moral dilemmas which occur through various episodes, and often some interesting conclusions to said problems. After watching the first season (I actually have one episode left, as of this writing), I started watching the films. Here are some thoughts on the ones I've seen so far.
I have two more films to go: Star Trek V: The Final Frontier and Star Trek VI: The Undiscovered Country. I'm looking forward to both. I'll probably tweet my thoughts on those two, once I've seen them.
I've recently been thinking about upgrading the operating system on my desktop computer at home. More specifically, I've been tossing around the idea of upgrading to the 64-bit variant of Windows 7. Windows XP has been a decent operating system, but it's definitely feeling its age. Seeing as Windows 7 is being targeted for release on October 22, which is now less than 3 months away, I figured now is a good time to think about how I would upgrade.
Moving to a 64-bit OS would allow me to expand the amount of installed memory in my system. At a minimum, I would go to 4 GB installed, especially since Microsoft recommends at least 2 GB for the 64-bit flavor. To be safe, I think I might also buy some new hard drives and install the OS on those (keeping my current setup intact).
At $199 (for the full Home Premium version; $119 for an upgrade, which I have yet to read about), it seems quite an investment. Has anyone else thought about upgrading to Windows 7? Or is anyone currently running a 64-bit OS? If so, what are your thoughts?
I recently purchased a copy of Far Cry 2 on Steam. Oddly enough, Far Cry 2 has nothing to do with the first Far Cry, save for the name. Crytek, the original game's developer, wasn't involved in the development of Far Cry 2, so I'm confused as to why this game is billed as the true sequel. Other than the standard first person shooter tropes, the two have very little (if anything) in common.
To me, Far Cry 2 resembles the Grand Theft Auto series more than any traditional first person shooter. The mission design feels similar, as do many of the game mechanics. But in the long run, how does the game fare? Here's my review.
This game had a lot going for it, but in the end I was mostly let down. Thankfully, I only paid $20 for it.
It seems like every web browser these days is spending an enormous amount of time and development effort on JavaScript performance. Whether it's the new TraceMonkey engine in Firefox 3.5, the V8 engine in Google Chrome, or the upcoming SquirrelFish engine in WebKit browsers, everyone claims (to some degree) superiority in this arms race. All of this raises two questions in my mind.
1. How important is JavaScript performance? Are JavaScript applications really that slow? I'll admit that the new Firefox 3.5 browser feels snappier on sites like GMail and Netflix, but said sites never felt that slow before. Why are developers spending so much time optimizing something that not everyone uses? Admittedly, JavaScript usage is going up (especially with the Web 2.0 craze), but how much latency does JavaScript computing really account for in today's world? I'm much more concerned about data transfer; that's the bottleneck I see. Broadband speeds here in the United States are ridiculously slow, compared to other parts of the world. Shouldn't we all focus on ways to improve that? Yes, I know software developers have little control over that kind of infrastructure, but perhaps there are better protocols out there to get data to the end user in a more efficient manner.
2. Won't improved JavaScript performance lead to poorer JavaScript programming? As computers have gotten faster over the past two decades, and as memory sizes have increased, applications have become more bloated and (arguably) slower than before. I'm convinced that if programmers had retained the "every byte matters" mentality from the 1970s, 80s, and early 90s, applications would be leaner and meaner than they are today (especially in the realm of operating systems). Can't the same thing be said for JavaScript programming? As JavaScript engines get faster, serious performance considerations during an application's design phase might become less and less frequent. I'm of the opinion that high performance hardware can lead to sloppy programming. "Well, the application is good enough" is what the pointy-haired bosses of the world would say. Shouldn't the application be the best it can be? Can't one argue that "good enough" isn't necessarily good enough?
I'll be interested to see where this arms race takes us. What do you think?
The Disk Cleanup utility that comes as a part of Windows has an annoying feature. As a part of its scan procedure, it tries to figure out how much space you'd save by "compressing old files." This step takes a ridiculously long time to complete, and is highly annoying. Thankfully, disabling this feature is simple, though it involves editing your Windows registry. As always, be very careful during the editing process.
To disable the "Compress Old Files" operation, navigate to this registry key, and delete it:
HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows\CurrentVersion\Explorer\VolumeCaches\Compress old files
Once you've deleted the above key, start up the Disk Cleanup utility and marvel at how much faster it loads!
My dad has just posted some details on how he's reducing the humidity under his house. It's a pretty cool solution that utilizes 'SmartVents' (essentially a vent with some muffin fans and the appropriate sensors). Head on over to the article to get the full details.
Is anyone else seeing a slow startup issue with Firefox 3.5? I'm talking about the initial load (after turning on your computer, for example). For me, startup times have increased dramatically with 3.5, and I've even tried creating a new profile. On my machine at home, cold startup takes between 30 and 60 seconds. On my laptop, it's between 15 and 30 seconds. Firefox 3.0.11 took on the order of 5 or 10 seconds on both machines.
I've got to believe something is wrong with 3.5. Maybe a 3.5.1 is on the horizon...
Update: According to commenter Dean, cleaning out your temporary directory should help things (and it worked for me). To locate the temp folder, open a command prompt and type echo %TEMP%. For me, the folder was under "Documents and Settings\Jonah\Local Settings\Temp." I cleaned this out using the Disk Cleanup utility (mine was 750 MB in size!) and startup was much faster (10 seconds or so).
Update 2: I've found the requisite bug about this problem on Bugzilla: bug 501605. If I read this correctly, NSS uses files in the temporary folder to seed its random number generator. If you have tons of files, this operation takes a long time (the file scan operation isn't as efficient as it should be). There may also be other factors (as commenters in the bug report suggest), but this is at least one of the problem areas.
The latest and greatest version of Firefox is now available. There are a lot of new features and fixes in this release, including HTML 5 support, the new TraceMonkey JavaScript engine, Private Browsing, and lots more.
Both CoLT and Googlebar Lite are compatible with the new release, so make sure you're up to date with both.
I've bitten the proverbial bullet and joined twitter. You can follow me (if you're so inclined) at my oh-so-clever username: jonahbishop. I'll be using the service for small things that aren't quite worth a blog post (it will not take the place of this site). We'll see how it goes over time.
Frustratingly enough, when I signed up for twitter, the site was having major problems. Thankfully, things seem to be back to normal now. I've noticed a strange thing with the service, however. After climbing into the twitter pool, I noticed a number of leeches attaching themselves to my account. In other words, a number of random people started following me for no apparent reason (I recognize none of them). Does anyone else here who uses twitter see the same thing? Is there a way to stop it? Are these people simply spammers out to get "trackback" style web-cred?
The 30th annual Festival for the Eno is coming up next weekend, July 3-5. If you're in the Triangle area in North Carolina, be sure to check it out. Tickets are $15 at the gate, and most (if not all) of the money goes to conserving the Eno River. The event is "trash free" (over 90% of trash is either recycled or composted) and a great way to spend a day. Over 80 musical and dance groups will be performing on 4 stages during the 3 days. Add to this great food, art vendors, and the beautiful West Point on the Eno setting, and you have a recipe for a great time.
I'll most likely be out there on Friday; if you see me, be sure to say hello!
Recently, I've been doing a lot of thinking about backup strategies for my data. I'm bad about not backing things up on a regular basis, and I'm hoping to change that. There are a number of routes one can take, and I've been looking at several.
The easiest solution is to backup data onto removable media (CD, DVD, or an external hard drive). This method is cheapest, but it also has some serious drawbacks. CDs and DVDs have relatively small data footprints, which means you have to use many discs to backup sizable data stores. Writable discs also don't last forever. The most serious flaw with this strategy, however, is that the backups are not off site. If someone breaks in and steals my computer, they are almost certain to also take the external hard drive sitting next to it. The same can be said for a fire; if the machine burns, so does the hard drive.
A number of online services are available for doing data backup. Carbonite and Mozy are two of the bigger ones I've heard about. These services give you off site backups, but they too have drawbacks. Often, these services have software that runs all the time on your machine, incrementally backing up as you go (which may be something you don't want). In some cases, you also have limited control over exactly what gets backed up. The services cost money, and you're giving your data to a third party. And, with lousy broadband in the US, initial upload times for large data can be painfully slow.
What does everyone here do to backup their data? Can anyone recommend a service or strategy that works well for them?
If you use WordPress, I advise against upgrading to version 2.8. I attempted to do so to this site this evening (via Subversion), and everything appeared to go smoothly. Unfortunately, upon logging in to my admin panel, I noted that everything was broken. The external site still performed as expected, but I couldn't get around in the admin area.
Zero steps forward, twenty steps back.
Maybe others will have better luck than I did. I have since reverted back to 2.7.1 for the time being, though my database may now be corrupt. If you notice anything funky around this site, please, please, please let me know.
A recent trend among websites for games that have a "M for Mature" (or similar) rating is the use of age gates. These gates require the user to enter their birth date before they can view information on the subject in question. Usually, the user is presented with three pull down menus: one for the month, one for the day, and one for the year. From a legal perspective, I can understand why companies want to use this feature. But who are these gates really keeping out? Every kid should know that by providing an old enough date, they can gain access to the site. After all, this isn't rocket science.
Every time I visit a website with one of these gates, I enter the most ridiculous date possible by selecting the oldest year offered (usually 1900). Maybe if enough people enter ridiculous dates every time, this annoying website 'feature' will go away.