Dustin and his wife recently uncovered an interesting limitation of my Monkey Album software: characters outside of the ISO-8859-1 (Latin 1) character set don't render properly. This comes as no surprise, seeing as I didn't design for Unicode. Being a rather egregious display error, I decided to set out and fix the problem. In the process, I learned quite a lot about Unicode, and how it affects web applications. This post will be the first of two detailing how to add Unicode support to a web application. I will only be exposing a tip of the Unicode iceberg in these posts. The ideas and practices behind Unicode support can (and do) fill the pages of many books. That said, let's jump in.
Brief Background
For the uninitiated, Unicode is a coded character set. That is, it maps a unique scalar value (a code point) to each character in a character set. ASCII is another example of a coded character set. Each character in a coded character set is intended to be encoded using a character encoding scheme. ISO-8859-1 is an example of a character encoding scheme.
It is important to note that ISO-8859-1 is the default encoding for documents on the web served via HTTP with a MIME type beginning with "text/". So, if you're not set up to specifically serve another encoding, your web pages are most likely using ISO-8859-1. This works just fine if you speak English or a subset of European languages. But because the ISO-8859-1 character encoding uses only 8 bits for its encoding scheme, it is limited to 256 possible characters. It turns out that 256 characters isn't enough for international text representation (the Chinese and Japanese languages come to mind). What can we do?
Thankfully, we have a solution in Unicode. A number of Unicode encoding schemes are available for us to use: UTF-7, UTF-8, UTF-16, and UTF-32. Each has its merits and detractors, but it turns out that UTF-8 is the preferred encoding of choice in the computing world (it's a nice trade off between space allocation and capability). As a bonus, UTF-8 works nicely with ASCII, which makes migrating English-based websites much easier.
Unfortunately, we have another major problem to deal with. All PHP releases (prior to the upcoming PHP 6) internally represent a character with 8-bits. That's right: PHP has no native support for international characters (yet)! This means that we have to be extra vigilant in our pursuit of internationalization support. So how do we do it?
Prepping Our PHP for Unicode
In order for our PHP application to properly display Unicode characters, we need to do some preparatory work. This involves setting the appropriate character encoding in a few places. We'll first set the encoding in the header:
header('Content-Type: text/html; charset=UTF-8');Remember that the header() function must be called before we output any HTML, so it needs to appear early in the chain of events. Note also that the header call incorrectly labels the encoding as a 'charset,' making the naming conventions even more confusing.
We can also specify the encoding through the use of a meta tag (I recommend setting this even if you set the header):
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">If you take this route, make sure this tag is placed near the top of the <head> element in your HTML (before your <title> element, in fact). Otherwise, the browser may select an incorrect encoding.
To verify that that the appropriate encoding is being used, you can use the View Page Info feature in Firefox (just right click the page and you'll see it in the context menu). Here's an example:
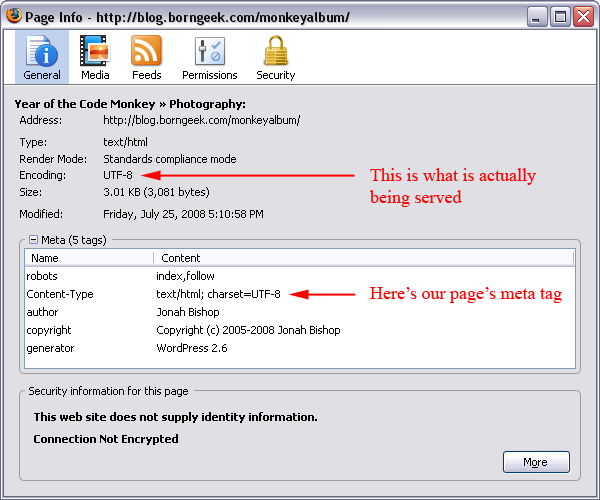
Displaying Unicode Text
One of the primary functions that PHP provides to convert characters into their HTML entity equivalents is the aptly named htmlentities() function. However, since we're converting our application to support UTF-8, we don't need to make use of this function. Why is this? First, HTML entities are generally only understood by web browsers. By converting special characters into HTML entity equivalents, it becomes much harder to move data between the web application and other data sources (RSS feeds, for example). Second, and most importantly, UTF-8 allows us to display extended characters directly. To quote Harry Fuecks [PDF], with UTF-8 "we don't need no stinkin' entities." Instead, we should only worry about the "special five":
- Ampersand (&)
- Double Quote (")
- Single Quote (')
- Less Than (<)
- Greater Than (>)
Thankfully, PHP gives us the htmlspecialchars() function to handle these five special characters. One very important thing to note is that this function allows you to specify the character encoding to use when parsing the supplied text. For example:
htmlspecialchars($incomingString, ENT_QUOTES, "UTF-8");Specifying the character encoding is very important when using this function! Otherwise, you open yourself up to to a rather nasty cross-site-scripting vulnerability, something that even Google was susceptible to a while back. In short, the character encoding specified in your htmlspecialchars() call should match the encoding being served by the page.
What Next?
In the next article, I'll cover the following topics:
- Prepping MySQL databases for Unicode
- Accepting Unicode characters from the user
- Potential PHP pitfalls
- Useful resources (loads of helpful links)
As always, if you have suggestions or questions, feel free to post them.